
Google lleva indexando y ordenando la web más de 20 años, configurándose como el motor de búsqueda con mayor cuota de mercado en occidente gracias a unos algoritmos que no dejan de cambiar y modificar la forma en la que encontramos contenido en Internet. El objetivo de Google es simple: que encontremos lo que buscamos, exactamente lo que buscamos, en el menor tiempo posible, y para ello han desarrollado BERT, siglas de "Bidirectional Encoder Representations from Transformers".
BERT, en pocas palabras, es el siguiente paso de Google Search. Usando inteligencia artificial, Google quiere que su buscador no solo reconozca los términos clave de una búsqueda, sino que entienda su contexto. Porque la palabra "cambiar" tiene diferentes acepciones y no es lo mismo cambiar cromos que cambiar una rueda. Esta tecnología, según nos ha explicado Pandu Nayak, VP de Google Search, llegará a lo largo de la semana en más de 70 idiomas, español incluido, así que vamos a ver cómo funciona y en qué consiste.
El contexto es la clave
Lo primero que tenemos que saber es cómo funciona Google. Grosso modo, cuando buscamos "comprar móvil barato" Google analiza esos tres términos y busca en su enorme, enormísimo índice, el contenido que tiene esas palabras exactas. Para Nayak, "esto no es para nada suficiente". ¿Por qué? Porque según nos explica el VP de Google, "recibimos montones y montones y montones de consultas de todo tipo en los que la coincidencia de términos no funciona". Tanto es así, que el 15% de las búsquedas que se hacen diariamente en Google son nuevas, es decir, que no se han hecho nunca.
La clave para dar respuesta a estas búsquedas nuevas está en el contexto, en entender qué busca exactamente el usuario y qué significa exactamente cada palabra. Usemos la búsqueda "cambiar el brillo del portátil". "Cambiar" ahí no significa cambiar como sustituir una cosa por otra, sino "ajustar". Lo más normal es que cuando buscamos "cambiar el brillo del portátil" realmente queramos acceder a un tutorial sobre "ajustar el brillo del portátil". Google debe saber ese contexto para devolver un resultado correcto.
Pero va más allá. Cuando buscamos en Google, el motor desecha algunos términos que pueden cambiar radicalmente el resultado que obtenemos. Volvemos a verlo con un ejemplo: "puedo comprar medicinas para alguien farmacia". Ahí, según nos explica Nayak, Google se queda con los términos "comprar medicinas" y "farmacia", pero desecha "para alguien", por lo que el resultado que nos mostrará no es exactamente el que necesitamos. Nos mostrará, quizá, farmacias online o farmacias cerca, pero no la regulación sobre comprar medicamentos para otra persona, que es lo que queremos saber. "Eso es el tipo de cosas en las que tenemos que trabajar", afirma Nayak, y ahí entra BERT.
BERT nace en Google AI Research y cuando se publicó su paper en octubre de 2018 "causó un gran impacto en la comunidad de investigación porque mejoró drásticamente alrededor de una docena de problemas de comprensión del lenguaje en los que la comunidad de investigación estaba trabajando", apunta Nayak. Se trata de un modelo de machine learning que, curiosamente, se remonta a una idea del lingüista británico John Rupert Firth, que ya en los años 60 dijo que se puede conocer el significado de una palabra por su compañía.
"Todos los sistemas de comprensión del lenguaje se han inspirado mucho en esa misma idea de mirar el contexto en el que se usan las palabras, pero los sistemas del pasado, todos los sistemas del pasado, sólo han tomado cantidades limitadas de contexto", apunta el VP de Google. "La innovación de BERT es que puede tomar mucho contexto, puede tomar muchas palabras antes y muchas palabras después".
"BERT analiza todas las palabras de una búsqueda para entender el contexto de la misma y ofrecer resultados más acordes"
BERT ha sido entrenado usando las búsquedas que los usuarios han hecho en Google y documentos del índice de Google de una forma interesante: buscando la palabra clave exacta que mejor encajaría en un texto en el que esa palabra falta. De nuevo, un ejemplo:
El xxx es el tipo de vegetación dominante en muchos xxx, incluidas las marismas salinas, pantanos y estepas. Los biomas dominados por pastos se XXX praderas. Estos biomas cubren el 31% del XXX de la Tierra. Los pastos son buenos para muchos XXX que pastan, como el ganado, los ciervos y los pequeños roedores como los ratones y los ratones de campo.
Si leemos ese texto, nosotros podemos intuir cuáles son las palabras que faltan por todo el contexto del mismo. Google, tal y como funciona ahora mismo, no, pero con BERT, dicen, sí, ya que analiza todas y cada una de las palabras que aparecen en el texto para predecir que faltan "pasto", "hábitats", "llaman", "suelo" y "mamíferos".
"Resulta que esta comprensión de las palabras puede ser muy potente para mejorar muchas y muy diversas tareas de lenguaje natural", dice Nayak, que afirma que "a principios de este año comenzamos a trabajar en formas de coger estas ideas y utilizarlas para mejorar Search por nosotros mismos". "Reentrenamos (BERT) usando consultas y documentos de nuestro índice y así sucesivamente. Pero tomamos las ideas esenciales y ciertamente tomamos la arquitectura. Lo usamos para producir una señal que luego incorporamos a nuestro sistema de clasificación".
"Para entrenar BERT, Google ha cruzado las búsquedas realizadas por los usuarios y los documentos de su índice"
BERT usa "transformadores", una arquitectura de red neuronal del lenguaje que "aplica un mecanismo de auto atención que modela directamente las relaciones entre todas las palabras en una oración, independientemente de su posición respectiva". Como explican desde Google:
"Para calcular la representación de una palabra dada [...] el transformador la compara con cualquier otra palabra en la oración. El resultado de estas comparaciones es una puntuación de atención por cada palabra en la oración. [...] Estas puntuaciones de atención determinan cuánto debe contribuir cada una de las otras palabras a la siguiente representación de la palabra (que tiene que predecir)".
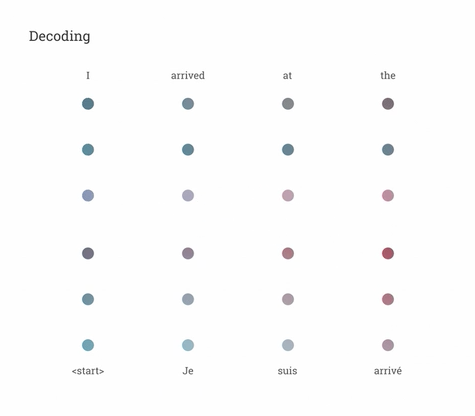
Aunque este ejemplo es de transformadores aplicados a la traducción, nos sirve para entender cómo funcionan. Las cuatro palabras que componen la frase inicial se analizan para predecir qué importancia tiene cada palabra en el contexto de la frase, cuál va primero y qué quiere decir el usuario cuando busca dicha frase.
En otras palabras, son las propias palabras (valga la redundancia) las que indican al modelo cómo debe interpretar la palabra que está buscando para predecir el resultado más probable. Es decir, le dice al modelo que en la búsqueda "cambiar brillo del portátil" la palabra "cambiar" realmente es "ajustar", ya que se adecúa más a los términos "brillo" y "portátil".
De acuerdo a Nayak, sus resultados apuntan a que "entre el 10% y el 20% de las búsquedas han sido significativamente impactadas por este cambio en la mayoría de idiomas populares". Opina que "ha sido un buen impacto" y que se trata de "una de las mejoras más grandes que hemos hecho en Search en los últimos cinco años y la más importante que hemos hecho desde los inicios".
El modelo se ha evaluado mediante una especie de examen que sigue las "Rater guidelines" de Google (son públicas). Entre 10.000 y 15.000 personas fueron expuestas a dos resultados de una misma búsqueda (digamos, "comprar medicinas para alguien farmacia") y tuvieron que evaluar si el resultado satisfacía la búsqueda y la calidad/reputación de la página mostrada, es decir, si Google devolvía un post genérico de comprar medicinas o si, por el contrario, mostraba un artículo de una fuente fiable explicando si puedes o no hacer eso. Esto se conoce como side by side experiment.
"Según Nayak, entre el 15% y el 20% de las búsquedas han sido impactadas tras la implementación de BERT"
Por supuesto, el modelo no es perfecto. Después de todo, el idioma es un asunto complejo y entender el contexto de una búsqueda no es fácil. Según nos explicó Nayak, en las primeras versiones de BERT se fallaba con las búsquedas visuales, por ejemplo "tartán" (el tejido de las faldas escocesas). Si alguien buscaba "tartan qué es", BERT entendía que quería saber su definición, por lo que en lugar de mostrar una foto mostraba una definición del diccionario, "así que tuvimos que hacer algunos cambios para mejorar en las búsquedas en los que la representación visual era preferible".
Algo parecido ocurre con las búsquedas en diferentes idiomas, digamos un inglés que busca algo en español. En las primeras versiones de BERT, al buscar un término en español Google ignoraba las páginas españolas (Wikipedia en español, por ejemplo) y mostraba resultados relacionados con el término en inglés (como la Wikipedia en inglés). En la versión final, según nos cuenta, este problema parece haberse corregido y BERT entiende que si buscamos algo en otro idioma queremos recibir los resultados en dicho idioma, no en el nuestro. Esto es importante en muchos países europeos, donde se hablan varios idiomas.
Primero en Google, puede que luego en otros productos

Nayak también contestó a algunas preguntas relacionadas con la implementación de BERT. Por un lado, respecto a su lanzamiento, nos confirmó que, salvo que haya algún problema, BERT debería empezar a funcionar en todo el mundo a lo largo de esta semana en la búsqueda de Google. Esto, según pudimos saber, afectará también a todo lo que suponga buscar en Google, como usar Google Assistant con la voz para obtener información sobre algo.
En cuanto a la integración con otros productos de la compañía, Nayak dijo que "este sistema en particular es sólo para la búsqueda en la web, pero las ideas en torno a BERT, a este modelo de lenguaje masivo, están encontrando mucho interés en una variedad de áreas diferentes, tanto en Google, como fuera de Google, por lo que hay algo muy interesante ocurriendo aquí y creo que veremos muchos más usos de esta idea a través de muchos de nuestros productos". ¿Cuáles? Seguramente toque esperar para saberlo.
"BERT es un proyecto de código abierto, así que cualquier persona o empresa puede acceder a él para implementarlo en sus productos"
Por otro lado, Nayak también se pronunció al respecto de si este modelo acabará provocando que menos personas hagan clic en un enlace. Es un tema que ha generado cierta controversia en más de una ocasión. En ese sentido, Nayak cree que "lo que este sistema está haciendo es comprender mejor el matiz en la pregunta que el usuario está haciendo" y que "BERT nos está ayudando a sacar a la superficie el resultado correcto que el usuario puede clicar para conocer los detalles".
Finalmente, en lo referente a si otros motores de búsqueda como Yandex o Baidu tienen algo como BERT, el VP de Google dijo que tiene "motivos para crear que todo el mundo está investigando BERT para ver qué puede hacer con él". Y es que BERT es de código abierto, por lo que cualquier persona puede acceder al proyecto, al código, y adaptarlo a sus necesidades.
Fuente: xataka.com








